Seldonian ML
GitHub
Example: Gender bias in facial recognition
Contents
Introduction
In the last decade, the use of facial recognition technology (FRT) has become widespread in society. This is largely due to companies and governments leveraging the significant improvements in accuracy that deep learning models have been able to achieve compared to previous methods. Under certain controlled conditions, for example matching a well-lit and well-aligned picture of a face to a database of passport photos, accuracy of state-of-the-art models can reach human levels.1 Of the many applications of FRTs, some include helping to find missing people,2,3 performing identity checks on people passing through international borders
,4 matching images of alleged criminals to databases of known offenders,5,6 "tagging" faces in social media applications, and unlocking smartphones and other personal devices.
While many of the applications of FRT appear to have positive or possibly neutral societal outcomes, like other machine learning (ML) technologies, FRTs have the potential to exhibit and even amplify inequalities that already exist in the world.7 For example, Buolamwini & Gebru (2018) analyzed three commercial gender classification FRT systems, finding that females, in particular dark-skinned females, were misclassified more than their male counterparts.8 In the worst case, the error rate for dark-skinned females was more than $34\%$ worse than that for light-skinned males. It is easy to imagine how this disparity could result in discrimination against sensitive groups through the applications of FRT.
In response to the findings like those of Buolamwini & Gebru (2018), as well as mounting pressure from the American Civil Liberties Union and other civil rights organizations, several large technology companies including Amazon, IBM, Microsoft, and Facebook have since announced that they will either temporarily cease or altogether discontinue developing and/or selling their FRTs to law enforcement departments.9,10,11 Despite these concessions, FRTs are still widely used, with little to no federal regulation governing how they can be applied in the United States. Barring extreme federal regulation, FRTs are unlikely to disappear from society in the near future.
In the absence of federal regulation in the United States, some states and municipalities have already begun to adopt their own laws and restrictions.12 Rather than abandon the technology altogether, some companies have invested resources towards understanding and attempting to mitigate biases present in FRT systems.13,14 These companies are best poised to adapt their FRTs as regulations arise. Many of the mitigation methods rely on having a "balanced" dataset, i.e., one where the relative proportions of sensitive attributes in the dataset (e.g., race, gender) are similar. Most of the original benchmark facial recognition datasets were not balanced, so it is reasonable to rectify that imbalance. However, fixing the imbalance alone will not always sufficiently reduce bias.15 It is also not always practical to have a fully balanced dataset in terms of all attributes.
The Seldonian Toolkit is uniquely poised to mitigate certain types of biases in FRTs for three reasons:
- The toolkit does not require the dataset to be balanced, although in some cases it may be more data-efficient when the dataset is balanced.
- It provides high-confidence guarantees that the fairness constraints will hold on unseen data, as long as the new data comes from the same distribution as the training data. As far as we are aware, no other methods provide such a guarantee.
- Because fairness-aware facial recognition research is still in its infancy, it is not yet clear what the best fairness metrics are. The toolkit allows one to define custom fairness constraints, making it easy to adapt to new definitions, such as ones that might be required by new regulations. This flexibility also makes it a good tool for exploring different fairness definitions.
In this example, we show how to enforce statistical fairness guarantees on an example FRT in the form of a gender classification system using the Seldonian Toolkit. First, we want to stress that there are, in addition to enforcing statistical fairness guarantees, likely other challenges to overcome to make sure that FRTs are fair. In any attempt to make FRT fair, it seems likely that there will be a need for one component to ensure that trained ML models do not provide these types of bias. The toolkit is one possible example of that component. We also want to stress that the fairness constraints we choose in this example are not intended to be correct or used in the real world. Instead, this example demonstrates how one could use the toolkit to apply a wide range of statistical fairness constraints to
any deep learning model used for facial recognition. The proper fairness definitions for FRTs should likely be determined by a team of social scientists, legislators, and members of the community.
Dataset preparation
We will train the gender classifier on the UTKFace dataset,16 a public dataset consisting of over 20,000 faces with annotations for gender, race, and age. The UTKFace webpage hosts the official dataset. The images vary in pose, facial expression, illumination, occlusion, and resolution. Like many large supervised learning datasets, the official dataset contains some mislabeling, and some images have letters and watermarks. We downloaded an aligned and cropped version of the dataset containing 23,705 faces in CSV format from here.


 Figure 1: Distribution of gender, race, and age attributes in the UTKFace dataset.
Figure 1: Distribution of gender, race, and age attributes in the UTKFace dataset.
 Figure 2: Ten random samples from the UTKFace dataset, demonstrating the diversity in personal attributes as well as image quality.
Figure 2: Ten random samples from the UTKFace dataset, demonstrating the diversity in personal attributes as well as image quality.
We used the following code to load, normalize, and shuffle the data. We then extracted the features, labels, and sensitive attributes. We used only the images for the features. The labels are the binary gender values (0=male, 1=female). The sensitive attributes are also the gender values. The toolkit requires any sensitive attributes to be one-hot encoded, so we make binary valued columns for gender - one where 1 indicates male and the other where 1 indicates female. We also clip off the last 5 data points (after shuffling) so that it will be easy to make all batches the same size when running gradient descent.
# format_data.py
import autograd.numpy as np # Thinly-wrapped version of Numpy
import pandas as pd
import os
from seldonian.utils.io_utils import load_pickle,save_pickle
N=23700 # Clips off 5 samples (at random) to make total divisible by 150,
# the desired batch size
savename_features = './features.pkl'
savename_labels = './labels.pkl'
savename_sensitive_attrs = './sensitive_attrs.pkl'
print("loading data...")
data = pd.read_csv('../../../facial_recognition/Kaggle_UTKFace/age_gender.csv')
# Shuffle data since it is in order of age, then gender
data = data.sample(n=len(data),random_state=42).iloc[:N]
# Convert pixels from string to numpy array
print("Converting pixels to array...")
data['pixels']=data['pixels'].apply(lambda x: np.array(x.split(), dtype="float32"))
# normalize pixels data
print("Normalizing and reshaping pixel data...")
data['pixels'] = data['pixels'].apply(lambda x: x/255)
# Reshape pixels array
X = np.array(data['pixels'].tolist())
## Converting pixels from 1D to 4D
features = X.reshape(X.shape[0],1,48,48)
# Extract gender labels
labels = data['gender'].values
# Make one-hot sensitive feature columns
M=data['gender'].values
mask=~(M.astype("bool"))
F=mask.astype('int64')
sensitive_attrs = np.hstack((M.reshape(-1,1),F.reshape(-1,1)))
# Save to pickle files
print("Saving features, labels, and sensitive_attrs to pickle files")
save_pickle(savename_features,features)
save_pickle(savename_labels,labels)
save_pickle(savename_sensitive_attrs,sensitive_attrs)
The preprocessing steps in the above code take a minute to run. We saved the features, labels and sensitive attributes to disk so that we can load these quantities from disk later, rather than recomputing them.
We consider the following definition of fairness, which ensures that the accuracies for male faces and female faces are within $20\%$ of each other. The constraint string for this definition is:
$\min((\mathrm{ACC} | [\mathrm{M}])/(\mathrm{ACC} | [\mathrm{F}]),(\mathrm{ACC} | [\mathrm{F}])/(\mathrm{ACC} | [\mathrm{M}])) \geq 0.8$,
where $\mathrm{ACC}$ is the measure function for accuracy, and $\mathrm{M}$ and $\mathrm{F}$ refer to the male and female sensitive attributes, respectively. We will enforce this constraint with a confidence level of $\delta=0.05$, i.e., we want to ensure it holds with $95\%$ confidence.
Note: We stress that this definition of fairness is just an example. By using it in this example, we are not suggesting that it is a correct fairness definition. The proper fairness definitions for FRTs should likely be determined by a team of social scientists, legislators, and members of the community.
Running the Seldonian Engine
The engine requires a spec object to run. The spec object takes as input a model, dataset, and parse trees, among other parameters. We will use a convolutional neural network (CNN) with four convolutional layers, implemented using PyTorch. For details on how to use PyTorch models in the toolkit, see Tutorial G: Creating your first Seldonian PyTorch model. The code for the model is shown below, which we save in a file called facial_recog_cnn.py in a folder where we plan to run the Seldonian Engine:
# facial_recog_cnn.py
from seldonian.models.pytorch_model import SupervisedPytorchBaseModel
import torch.nn as nn
import torch
class FacialRecogCNNModel(nn.Module):
def __init__(self):
super(FacialRecogCNNModel, self).__init__()
# Define all layers here
self.cnn1=nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, padding=1)
self.cnn2=nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3)
self.cnn3=nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3)
self.cnn4=nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3)
self.relu=nn.ReLU()
self.maxpool=nn.MaxPool2d(kernel_size=2)
self.Batch1=nn.BatchNorm2d(16)
self.Batch2=nn.BatchNorm2d(32)
self.Batch3=nn.BatchNorm2d(64)
self.Batch4=nn.BatchNorm2d(128)
# Fully connected 1 (readout)
self.fc1=nn.Linear(128 * 1 * 1, 128)
self.fc2=nn.Linear(128,256)
self.fc3=nn.Linear(256,2)
self.softmax=nn.Softmax(dim=1)
def forward(self, x):
# Call all layers here. This does the forward pass.
out=self.cnn1(x)
out=self.relu(out)
out=self.maxpool(out)
out=self.Batch1(out)
out=self.cnn2(out)
out=self.relu(out)
out=self.maxpool(out)
out=self.Batch2(out)
out=self.cnn3(out)
out=self.relu(out)
out=self.maxpool(out)
out=self.Batch3(out)
out=self.cnn4(out)
out=self.relu(out)
out=self.maxpool(out)
out=self.Batch4(out)
# Resize
# Original size: (100, 32, 7, 7)
# New out size: (100, 32*7*7)
out=torch.flatten(out,start_dim=1)
# Linear functions (readout)
out=self.fc1(out)
out=self.fc2(out)
out=self.fc3(out)
# Softmax to make probabilities
out=self.softmax(out)[:,1]
return out
class PytorchFacialRecog(SupervisedPytorchBaseModel):
def __init__(self,device):
""" Implements a CNN with PyTorch.
CNN consists of four hidden layers followed
by a linear + softmax output layer.
Inputs are N,1,48,48 where N is the number of them,
1 channel and 48x48 pixels.
"""
super().__init__(device)
def create_model(self,**kwargs):
""" Create the pytorch model and return it
"""
return FacialRecogCNNModel()
The model class PytorchFacialRecog is the Seldonian model, which is just a wrapper for the PyTorch model class FacialRecogCNNModel.
We will use this model, along with a dataset and parse trees to create the full specification object. Parse trees are objects created from the behavioral constraints. In our case, we have a single fairness constraint, so we create a single parse tree. We also specify the optimization strategy, mini-batch gradient descent with a batch size of 237 and 40 epochs. The candidate data have $23,\!700*0.5 = 11,\!850$ datapoints, so all 50 batches will be of equal size with a batch size of 237. We also define the primary objective function to be the binary logistic loss. We create the spec object and then run the engine in a file called run_engine.py. Note that in this file, we import the model class we just defined from the file above. The model file must be in the same folder as this script in order for the import to work.
# run_engine.py
from seldonian.spec import SupervisedSpec
from seldonian.dataset import SupervisedDataSet
from seldonian.utils.io_utils import load_pickle,save_pickle
from facial_recog_cnn import PytorchFacialRecog
from seldonian.models import objectives
from seldonian.seldonian_algorithm import SeldonianAlgorithm
from seldonian.parse_tree.parse_tree import (
make_parse_trees_from_constraints)
sub_regime = "classification"
N=23700
print("Loading features,labels,sensitive_attrs from file...")
features = load_pickle(savename_features)
labels = load_pickle(savename_labels)
sensitive_attrs = load_pickle(savename_sensitive_attrs)
assert len(features) == N
assert len(labels) == N
assert len(sensitive_attrs) == N
frac_data_in_safety = 0.5
sensitive_col_names = ['M','F']
meta_information = {}
meta_information['feature_col_names'] = ['img']
meta_information['label_col_names'] = ['label']
meta_information['sensitive_col_names'] = sensitive_col_names
meta_information['sub_regime'] = sub_regime
print("Making SupervisedDataSet...")
dataset = SupervisedDataSet(
features=features,
labels=labels,
sensitive_attrs=sensitive_attrs,
num_datapoints=N,
meta_information=meta_information)
constraint_strs = ['min((ACC | [M])/(ACC | [F]),(ACC | [F])/(ACC | [M])) >= 0.8']
deltas = [0.05]
print("Making parse trees for constraint(s):")
print(constraint_strs," with deltas: ", deltas)
parse_trees = make_parse_trees_from_constraints(
constraint_strs,deltas,regime=regime,
sub_regime=sub_regime,columns=sensitive_col_names)
# Put on Mac M1 GPU via Metal performance shader (MPS) device.
# For NVIDIA graphics cards use "cuda" as the device string.
device = torch.device("mps")
model = PytorchFacialRecog(device)
initial_solution_fn = model.get_model_params
spec = SupervisedSpec(
dataset=dataset,
model=model,
parse_trees=parse_trees,
frac_data_in_safety=frac_data_in_safety,
primary_objective=objectives.binary_logistic_loss,
use_builtin_primary_gradient_fn=False,
sub_regime=sub_regime,
initial_solution_fn=initial_solution_fn,
optimization_technique='gradient_descent',
optimizer='adam',
optimization_hyperparams={
'lambda_init' : np.array([0.5]),
'alpha_theta' : 0.001,
'alpha_lamb' : 0.001,
'beta_velocity' : 0.9,
'beta_rmsprop' : 0.95,
'use_batches' : True,
'batch_size' : 237,
'n_epochs' : 40,
'gradient_library': "autograd",
'hyper_search' : None,
'verbose' : True,
},
batch_size_safety=2000
)
save_pickle('./spec.pkl',spec,verbose=True)
SA = SeldonianAlgorithm(spec)
passed_safety,solution = SA.run(debug=True,write_cs_logfile=True)
If we run the above file, we find that the safety test passes. The gradient descent log is written out, and if we plot it we can see how the primary objective function and evolved during the optimization process.
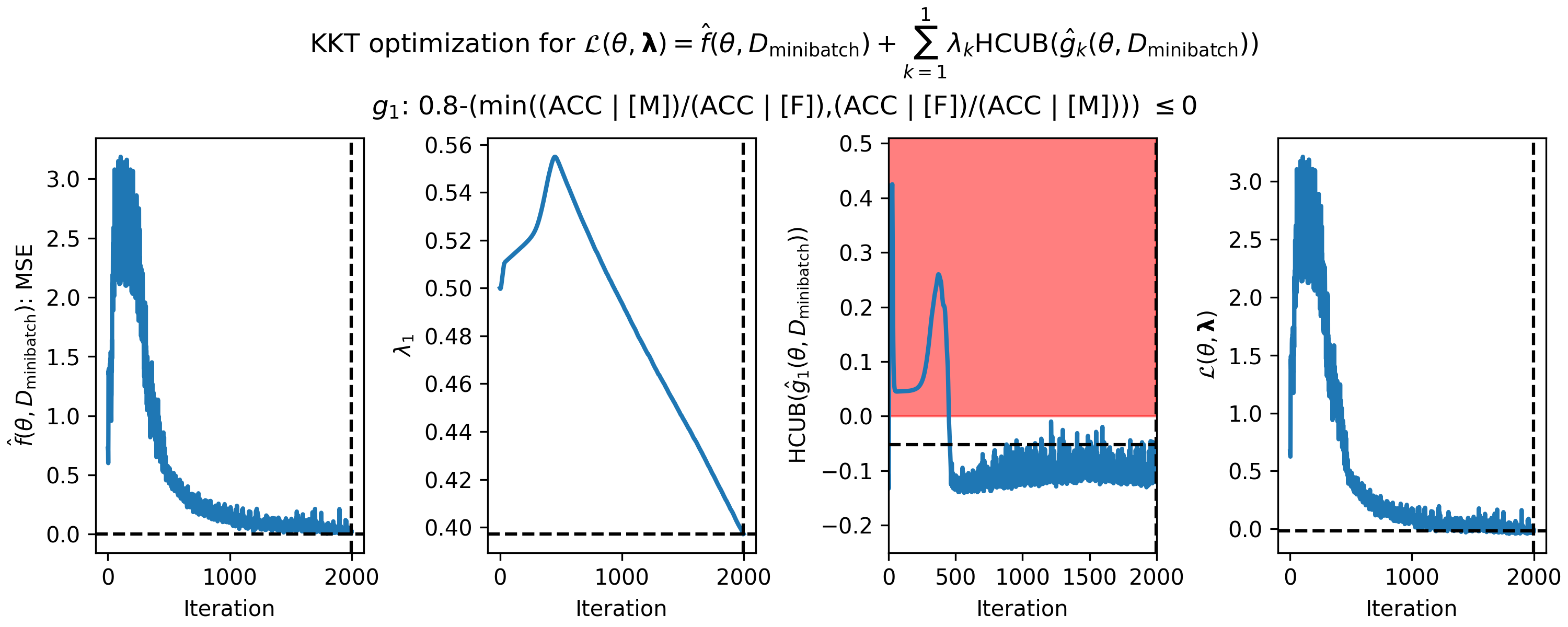 Figure 2: Gradient descent on the gender classification problem. The log loss (left) initially increases because the solution is predicted to fail the safety test (middle right). Solutions are eventually found that have both low log loss and are predicted to pass the safety test. The optimal solution is shown by the dotted black lines, i.e., the solution with the lowest log loss that is predicted to pass the safety test.
Figure 2: Gradient descent on the gender classification problem. The log loss (left) initially increases because the solution is predicted to fail the safety test (middle right). Solutions are eventually found that have both low log loss and are predicted to pass the safety test. The optimal solution is shown by the dotted black lines, i.e., the solution with the lowest log loss that is predicted to pass the safety test.
Running a Seldonian Experiment
Here we run a Seldonian Experiment, comparing the quasi-Seldonian model to two baseline models. The first baseline is the same CNN without the constraint, and the second is a weighted-random classifier that predicts that an image is of a woman with probability $p=\frac{N_{\text{women}}}{N_{\text{men}}} \simeq 0.477$, where $N_{\text{women}}$ and $N_{\text{men}}$ are the number of women and men in the entire dataset, respectively. This is done to establish a worst-case baseline for the performance. Let's set up the imports for the experiment:
import os, math
import numpy as np
import torch
from experiments.generate_plots import SupervisedPlotGenerator
from seldonian.utils.io_utils import load_pickle
from experiments.baselines.random_classifiers import (
WeightedRandomClassifierBaseline)
from experiments.baselines.facial_recog_cnn import PytorchFacialRecogBaseline
We will use 40 trials and a log-spaced data fraction array between 0.001 and 1.0, containing 15 distinct values. We will fix the batch size at 237 so that for a data fraction of 1.0, the number of samples in each batch will be equal, i.e., the last batch will not be smaller than all of the other batches. Because the number of datapoints input to the models varies with data fraction, if we left the number of epochs constant, the number of total iterations of gradient descent/ascent would be much smaller for the smaller data fractions. To keep the number of iterations of gradient descent/ascent fixed at 1200, we determine the number of epochs needed at each data fraction to do this. The batch_epoch_dict contains the batch sizes (fixed at 237) and number of epochs for each data fraction. We set the number of workers to 1 in this case because on the machine we ran this we only had access to a single GPU.
if __name__ == "__main__":
# Parameter setup
run_experiments = True
make_plots = True
save_plot = False
include_legend = True
performance_metric = 'Accuracy'
model_label_dict = {
'qsa':'Quasi-Seldonian CNN',
'facial_recog_cnn': 'CNN baseline (no constraint)',
'weighted_random_classifier': 'Weighted-random classifier'}
n_trials = 40
data_fracs = np.logspace(-3,0,15)
niter = 1200 # how many iterations we want in each run. Overfitting happens with more than this.
batch_size=237
data_sizes=data_fracs*11850 # number of points used in candidate selectionin each data frac
n_batches=data_sizes/batch_size # number of batches in each data frac
n_batches=np.array([math.ceil(x) for x in n_batches])
n_epochs_arr=niter/n_batches # number of epochs needed to get to 1200 iterations in each data frac
n_epochs_arr = np.array([math.ceil(x) for x in n_epochs_arr])
batch_epoch_dict = {data_fracs[ii]:[batch_size,n_epochs_arr[ii]] for ii in range(len(data_fracs))}
n_workers = 1
results_dir = f'../../results/facial_gender'
os.makedirs(results_dir,exist_ok=True)
plot_savename = os.path.join(results_dir,f'facial_gender_experiment.pdf')
verbose=False
Next, we set up the ground truth dataset used for calculating the performance and value of the constraints. For the performance metric we use the probabilistic accuracy, which is equivalent to $1-\text{error rate}$. We also batch the computations of the performance and constraints (this is for memory efficiency and does not change the results). We also set the PyTorch device for the experiment to be the same device that we used in the Engine, i.e., the Mac M1 GPU.
# Use entire original dataset as ground truth for test set
dataset = spec.dataset
test_features = dataset.features
test_labels = dataset.labels
# Setup performance evaluation function and kwargs
# of the performance evaluation function
def perf_eval_fn(y_pred,y,**kwargs):
if performance_metric == 'Accuracy':
# 1 - error rate
v = np.where(y!=1.0,1.0-y_pred,y_pred)
return sum(v)/len(v)
# Use same torch device as we used for running the Engine
device = spec.model.device
perf_eval_kwargs = {
'X':test_features,
'y':test_labels,
'device':device,
'eval_batch_size':2000
}
constraint_eval_kwargs = {
'eval_batch_size':2000
}
Although using the CPU will be much slower than the GPU for a single trial, if you have access to many CPUs and only one GPU, it could be faster to run the entire experiment across many CPUs. To do that, you would need to change n_workers above to the number of CPUs you want to use, and then replace the line device = spec.model.device above with the following two lines of code:
device = torch.device('cpu')
model.to(device)
We have not tested the experiments library with multiple GPUs, and we suspect that additional development work will be needed to enable distributing experiments across them. Next, we set up the plot generator needed to run the experiments.
plot_generator = SupervisedPlotGenerator(
spec=spec,
n_trials=n_trials,
data_fracs=data_fracs,
n_workers=n_workers,
datagen_method='resample',
perf_eval_fn=perf_eval_fn,
constraint_eval_fns=[],
constraint_eval_kwargs=constraint_eval_kwargs,
results_dir=results_dir,
perf_eval_kwargs=perf_eval_kwargs,
batch_epoch_dict=batch_epoch_dict
)
With the plot generator in hand, we are ready to run the baseline experiments and the quasi-Seldonian experiment.
# Baseline models first, then Seldonian
# First, set up CNN baseline
niter_min_baseline=25 # how many iterations we want in each run. Overfitting happens with more than this.
N_candidate_max=11850
batch_size_baseline=100
num_repeats=4
batch_epoch_dict_baseline = make_batch_epoch_dict_min_sample_repeat(
niter_min_baseline,
data_fracs,
N_candidate_max,
batch_size_baseline,
num_repeats)
facial_recog_baseline = PytorchFacialRecogBaseline(
device=torch.device('mps'),
learning_rate = 0.001,
batch_epoch_dict=batch_epoch_dict_baseline
)
wr_baseline = WeightedRandomClassifierBaseline(weight=0.477)
if run_experiments:
plot_generator.run_baseline_experiment(
baseline_model=wr_baseline,verbose=verbose)
plot_generator.run_baseline_experiment(
baseline_model=facial_recog_baseline,verbose=verbose)
# quasi-Seldonian experiment
plot_generator.run_seldonian_experiment(verbose=verbose)
Once those experiments are finished running, we can plot the results.
if make_plots:
plot_generator.make_plots(
model_label_dict=model_label_dict,fontsize=12,legend_fontsize=8,
performance_label=performance_metric,
performance_ylims=[0,1],
show_title=True,
custom_title=r'Constraint: $\operatorname{min}\left(\frac{ACC|[M]}{ACC|[F]},\frac{ACC|[F]}{ACC|[M]}\right) \geq 0.8$',
include_legend=include_legend,
savename=plot_savename if save_plot else None)
Below is the whole script altogether.
import os, math
import numpy as np
import torch
from experiments.generate_plots import SupervisedPlotGenerator
from seldonian.utils.io_utils import load_pickle
from experiments.baselines.random_classifiers import (
WeightedRandomClassifierBaseline)
from experiments.baselines.facial_recog_cnn import PytorchFacialRecogBaseline
if __name__ == "__main__":
# Parameter setup
run_experiments = True
make_plots = True
save_plot = False
include_legend = True
performance_metric = 'Accuracy'
model_label_dict = {
'qsa':'Quasi-Seldonian CNN',
'facial_recog_cnn': 'CNN baseline (no constraint)',
'weighted_random_classifier': 'Weighted-random classifier'}
n_trials = 40
data_fracs = np.logspace(-3,0,15)
niter = 1200 # how many iterations we want in each run. Overfitting happens with more than this.
batch_size=237
data_sizes=data_fracs*11850 # number of points used in candidate selectionin each data frac
n_batches=data_sizes/batch_size # number of batches in each data frac
n_batches=np.array([math.ceil(x) for x in n_batches])
n_epochs_arr=niter/n_batches # number of epochs needed to get to 1200 iterations in each data frac
n_epochs_arr = np.array([math.ceil(x) for x in n_epochs_arr])
batch_epoch_dict = {data_fracs[ii]:[batch_size,n_epochs_arr[ii]] for ii in range(len(data_fracs))}
n_workers = 1
results_dir = f'../../results/facial_gender'
os.makedirs(results_dir,exist_ok=True)
plot_savename = os.path.join(results_dir,f'facial_gender_experiment.pdf')
verbose=False
# Use entire original dataset as ground truth for test set
dataset = spec.dataset
test_features = dataset.features
test_labels = dataset.labels
# Setup performance evaluation function and kwargs
# of the performance evaluation function
def perf_eval_fn(y_pred,y,**kwargs):
if performance_metric == 'Accuracy':
# 1 - error rate
v = np.where(y!=1.0,1.0-y_pred,y_pred)
return sum(v)/len(v)
# Use same torch device as we used for running the Engine
device = spec.model.device
perf_eval_kwargs = {
'X':test_features,
'y':test_labels,
'device':device,
'eval_batch_size':2000
}
constraint_eval_kwargs = {
'eval_batch_size':2000
}
plot_generator = SupervisedPlotGenerator(
spec=spec,
n_trials=n_trials,
data_fracs=data_fracs,
n_workers=n_workers,
datagen_method='resample',
perf_eval_fn=perf_eval_fn,
constraint_eval_fns=[],
constraint_eval_kwargs=constraint_eval_kwargs,
results_dir=results_dir,
perf_eval_kwargs=perf_eval_kwargs,
batch_epoch_dict=batch_epoch_dict
)
# Baseline models first, then Seldonian
# First, set up CNN baseline
niter_min_baseline=25 # how many iterations we want in each run. Overfitting happens with more than this.
N_candidate_max=11850
batch_size_baseline=100
num_repeats=4
batch_epoch_dict_baseline = make_batch_epoch_dict_min_sample_repeat(
niter_min_baseline,
data_fracs,
N_candidate_max,
batch_size_baseline,
num_repeats)
facial_recog_baseline = PytorchFacialRecogBaseline(
device=torch.device('mps'),
learning_rate = 0.001,
batch_epoch_dict=batch_epoch_dict_baseline
)
wr_baseline = WeightedRandomClassifierBaseline(weight=0.477)
if run_experiments:
plot_generator.run_baseline_experiment(
baseline_model=wr_baseline,verbose=verbose)
plot_generator.run_baseline_experiment(
baseline_model=facial_recog_baseline,verbose=verbose)
# quasi-Seldonian experiment
plot_generator.run_seldonian_experiment(verbose=verbose)
if make_plots:
plot_generator.make_plots(
model_label_dict=model_label_dict,fontsize=12,legend_fontsize=8,
performance_label=performance_metric,
performance_ylims=[0,1],
show_title=True,
custom_title=r'Constraint: $\operatorname{min}\left(\frac{ACC|[M]}{ACC|[F]},\frac{ACC|[F]}{ACC|[M]}\right) \geq 0.8$',
include_legend=include_legend,
savename=plot_savename if save_plot else None)
When running the above code, the file with the model facial_recog_cnn.py must be in the same folder. Running the above code generates the following plot:
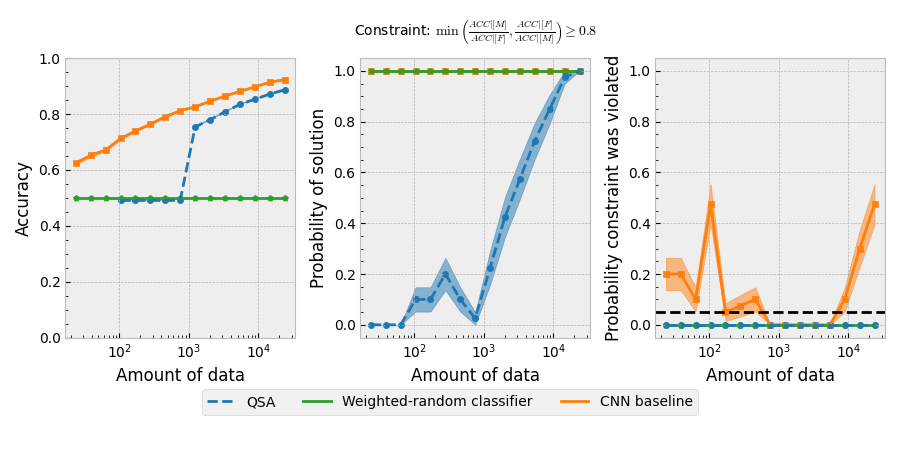 Figure 3: The left plot shows the accuracy (1 - error rate) of the model trained in this example (blue), a weighted-random classifier (green), and a baseline CNN trained in the absence of the constraint (orange). The middle plot shows the probability that the model will return a solution. The right plot shows the probability that the model’s predictions will violate the fairness constraint (shown at the top). Each plot’s horizontal axis is the amount of input data, which we varied in 15 log-spaced intervals from $0.001m$ to $m$, where $m$ = 23,700. We ran 40 trials at each amount of input data, plotting the mean and the standard error. The middle plot shows that the QSA returned NSF for all 40 trials for the smallest three amounts of data, so no accuracy is reported for those input data amounts. All other models always returned a solution. The black horizontal dashed line on the right plot indicates $\delta = 0.05$, the maximum probability we tolerate for the fairness constraint to be violated ($1 − 0.95 = \delta$).
Figure 3: The left plot shows the accuracy (1 - error rate) of the model trained in this example (blue), a weighted-random classifier (green), and a baseline CNN trained in the absence of the constraint (orange). The middle plot shows the probability that the model will return a solution. The right plot shows the probability that the model’s predictions will violate the fairness constraint (shown at the top). Each plot’s horizontal axis is the amount of input data, which we varied in 15 log-spaced intervals from $0.001m$ to $m$, where $m$ = 23,700. We ran 40 trials at each amount of input data, plotting the mean and the standard error. The middle plot shows that the QSA returned NSF for all 40 trials for the smallest three amounts of data, so no accuracy is reported for those input data amounts. All other models always returned a solution. The black horizontal dashed line on the right plot indicates $\delta = 0.05$, the maximum probability we tolerate for the fairness constraint to be violated ($1 − 0.95 = \delta$).
Discussion
The experiment plots show that if we train the CNN in the standard way without using any constraints, it violates the fairness constraint frequently (right panel of Figure 3). Importantly, that model does not become more fair as more data are used to train it. The fairness constraint is not all that restrictive - it only requires that the accuracies between males and females be within $20\%$ of each other. The CNN without the constraint is therefore quite biased in terms of its accuracy for faces of different genders. Using the Seldonian toolkit to create a quasi-Seldonian CNN trained subject to the fairness constraint, we achieve a model that never violates the constraint. The quasi-Seldonian model takes around 10,000 points before it will return a solution every time. With less data, the algorithm returns "No Solution Found," meaning that it was unable to find a safe solution. The accuracy of the quasi-Seldonian CNN approaches the accuracy of the CNN without the constraint, with a difference of $\sim4\%$. We stress that we did not perform rigorous hyperparameter tuning to achieve this result. It is likely that this gap could be narrowed further with tuning during candidate selection. The random classifier never violates the constraint because it has the same probability of predicting male or female regardless of the input image.
Summary
In this example, we demonstrated how to use the Seldonian Toolkit to build a gender classifier that satisfies a custom-defined fairness constraint. We covered how to format the dataset and metadata so that they are compatible with the toolkit. We ran the Seldonian Engine once to show that the model is capable of passing the safety test and to understand how the model is trading off its primary loss function with the constraint function. We then ran a Seldonian Experiment to evaluate the true performance and safety of the QSA and to compare it to baseline models. We found that the QSA performs almost as well as the CNN without any constraints after it has enough data to return a solution. Critically, the QSA never violates the constraint, whereas the CNN without constraints frequently violates it. The constraint is not all that restrictive, only requiring that the model's accuracy should not differ by more than $20\%$ when predicting one gender compared to the other.
We provide this example to show how to use to the Seldonian Toolkit to apply fairness constraints to a deep learning model and to evaluate how the performance, data-efficiency, and safety trade off. We want to stress that the dataset, model and fairness constraint we used are all interchangable. The toolkit supports any supervised deep learning model (as long as it is implemented in one of the supported libraries) and it is differentiable. Also, the fairness constraint we used is not intended to be correct or reused elsewhere. It was chosen as an example of how one could define their own fairness constraints or adopt existing ones. Enforcing this fairness constraint, or perhaps any, statistical fairness constraint(s) may not address all of the issues related to the fairness of facial recognition systems. There are other issues that go beyond enforcing statistical fairness constraints, such as concerns about consent from people whose faces are used to train the model and concerns about the use of facial recognition at all. Instead, we hope that the toolkit can be one piece of a more holistic solution that addresses these issues.